The question organizations ask most often about AI is some version of this: which use cases are worth pursuing, how do we make them actually work, and which ones can our organization realistically deliver right now? It is a fair question and a hard one, because the market answers it badly. Vendors present every use case as ready to deploy. Internal enthusiasts present the ones they find interesting. Almost no one starts where the answer actually begins, which is with the business deciding what outcome it wants and why.
This collection works through the most sought-after AI use cases one at a time, and for each it does the same thing: names the business value, lays out honestly what it takes to deliver, says what to ask and prepare before committing, and identifies the people, skills, and data work that make it land. The goal is not to rank use cases or sort them into tidy categories. It is to make a genuinely messy decision a little clearer, so you can tell the difference between a use case you can deliver this quarter and one that depends on work you have not done yet.
Two principles run underneath all of it.
The business defines the value, before anyone talks about data or models
The most common failure in enterprise AI is not technical. It is that a use case gets defined by IT, by a data team, or by a vendor, in terms of what is technically interesting or what the tool can do, rather than by the business in terms of an outcome it actually needs. When that happens, the project optimizes for a demo rather than a result, and it stalls the moment someone asks what business decision it changed.
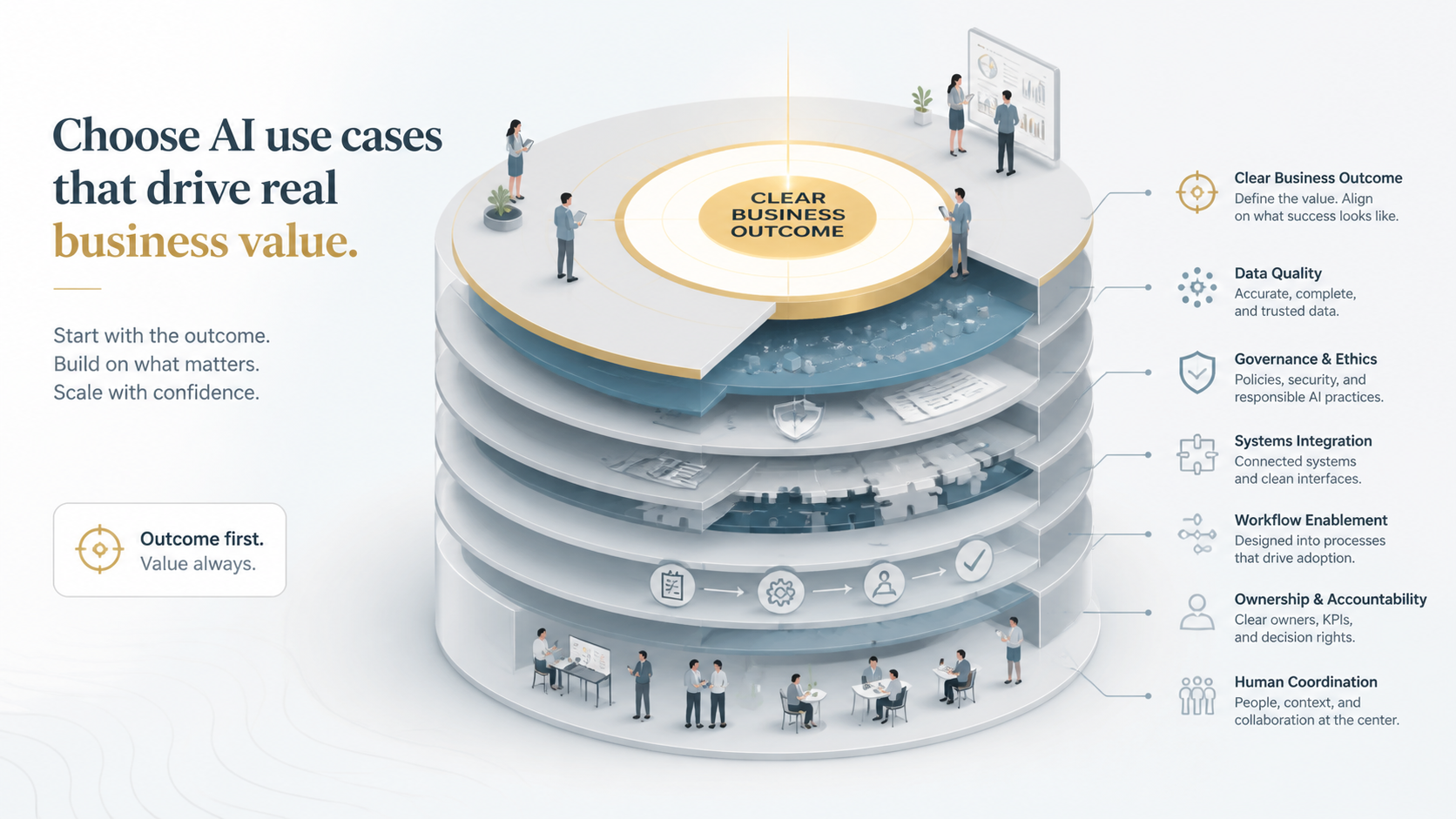
So the first move for any use case is for the business, the function that owns the outcome, to state the value in concrete terms. Not "we want AI in sales," but "we want to raise pipeline conversion by helping reps prioritize the accounts most likely to close, and we will measure it in conversion rate and rep productivity." Not "we want AI for maintenance," but "we want to cut unplanned downtime on this asset class, measured in hours and in avoided emergency repair cost." The owner is a business leader, the value is a named outcome, and the metric is specified up front. Everything downstream, the data work, the model, the integration, the governance, is in service of that outcome. If the business cannot state the outcome and the metric, the use case is not ready to evaluate, no matter how good the technology looks.
This sounds obvious and is routinely skipped, because starting from the technology is easier and more exciting. The discipline of starting from business-defined value is what separates the organizations that compound results from the ones that accumulate pilots.
Once the value is clear, the honest question is what it will take
With the outcome defined, the second principle applies: be honest about what delivering it actually requires, because that varies enormously and the variation is messy.
Some use cases ride on AI that a vendor has embedded into a product you already own, trained on the data that product already holds. These are usually the easiest to deliver, and they are a good place to start a discussion about quick wins. But it is worth saying clearly, because the market implies otherwise: embedded does not automatically mean clean. A vendor feature is only as good as the data it runs on, and plenty of embedded AI sits on top of data the customer never governed well, organizational structures that are out of date, knowledge bases that were never maintained, metric definitions nobody agreed on. Embedded lowers the barrier; it does not remove the data-quality question.
Other use cases depend on data that lives across many of your own systems and has never been cleaned, reconciled, or connected. Here the model is rarely the hard part. The work is in curating the data, establishing lineage so you can trace a result back to its source, resolving the same entity across systems, and assigning ownership for keeping it right. And many use cases sit somewhere in between, working well on the easy cases and hitting a wall the moment they need data the vendor tool cannot see or that your organization has not prepared.
Where a use case sits on that range, from clean embedded data through uncleaned multi-system data, is a useful diagnostic. It tells you roughly how much foundational work stands between you and the outcome. It is not a label to argue about, and it is not the most important thing about the use case. It is a way to set expectations and scope the effort honestly. The most important thing remains the business value. The diagnostic just tells you the price.
What each article gives you
For every use case that follows, the structure is consistent. First, the business value, stated as an outcome the business owns and can measure. Second, what it actually takes to deliver, the data reality, the quality and governance requirements, and the integration and oversight the use case depends on, surfaced through how this specific use case succeeds or fails rather than as a generic checklist. Third, what to ask, prepare, and put in place before and during implementation. And fourth, the resources that make it land: the people and roles you need, the skills you need in-house versus where outside help or a vendor genuinely earns its place, and the data work and tooling involved.
Each article ends where a real decision lives, with the readiness questions that tell you whether to pursue the use case now or do some preparation first. The aim across all of them is the same: help you start from the value you want, see clearly what standing between you and that value, and make a sober call about whether you are ready or what you would need to get ready.
The use cases ahead are the ones organizations ask about most, the ones that show up on nearly every AI roadmap. Some are more attainable than they look. Several are harder. The way to tell which is which is not to ask how impressive the technology is. It is to ask what business outcome you are after, and then to be honest about what that outcome will cost to deliver well.