The business value belongs to the risk and lending functions, and it has two parts that have to be defined together. The outcome is lower credit losses and better portfolio quality, and, inseparably, decisions that are defensible to regulators and to applicants. The owner is the chief risk officer or head of lending, with compliance as a co-owner because defensibility is not optional here; the metrics are loss rates, portfolio quality, decision speed, and the ability to explain and document any individual decision. The output is a score that drives a consequential decision about a person, and that fact governs everything the use case requires.
This use case sits at the demanding end of the delivery range, and not primarily because of data messiness. It is demanding because in a regulated environment the data foundation behind the model is a precondition for deployment, not an enhancement. A model that predicts default well but cannot be explained and traced is not a model you are allowed to put into production.
What it actually takes to deliver
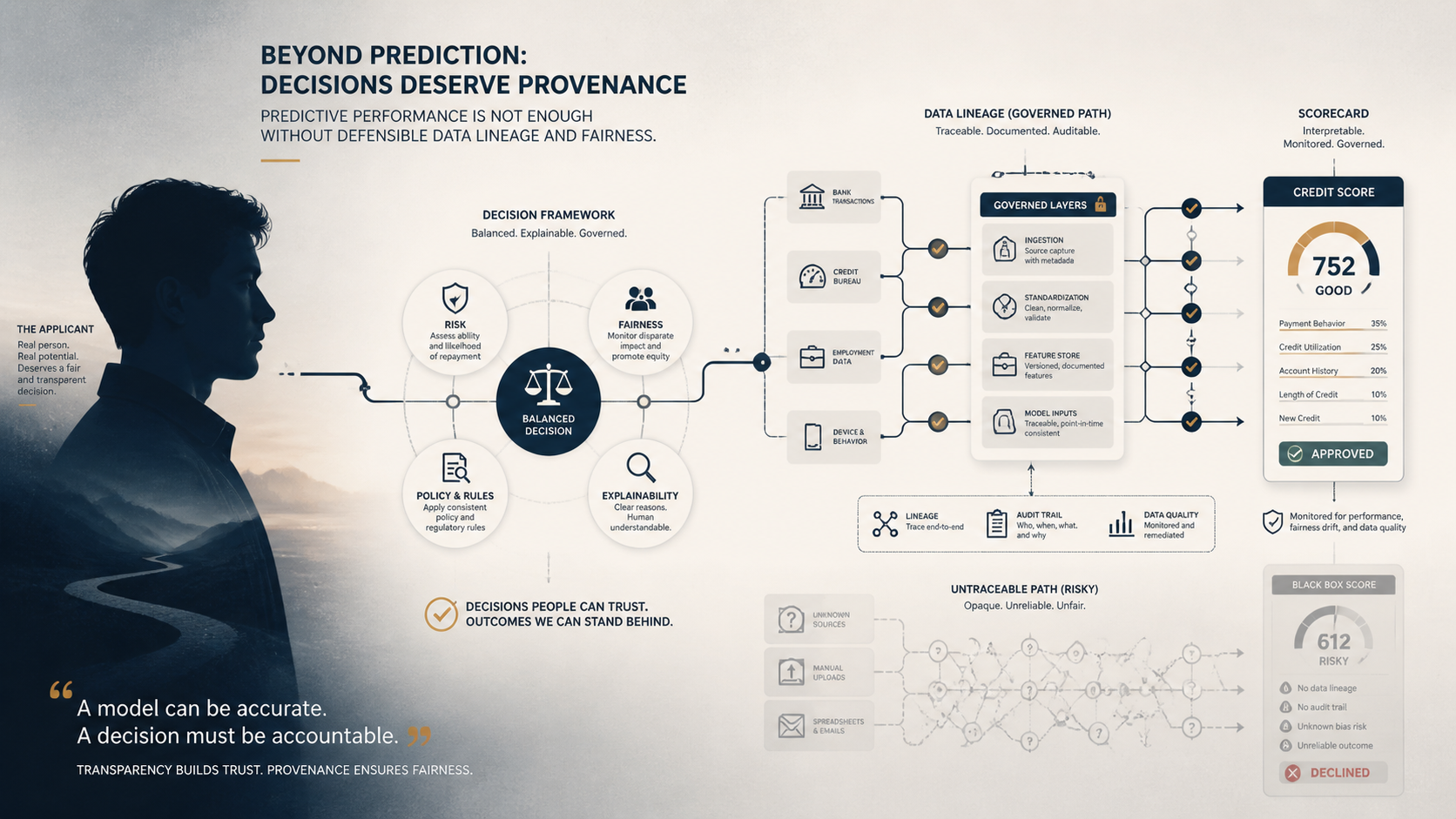
Building an accurate model is, by current standards, the easier half. A competent team can produce a model that beats a legacy scorecard. The bar in regulated lending is defensibility, and it rests on three things the model does not supply on its own.
The first is traceable feature construction. Every input has to be reconstructable: when the model uses average balance over the trailing twelve months, you must be able to show exactly how that value was computed, from which source records, through which transformations. A feature assembled from a pipeline no one can fully reconstruct cannot support a decision you have to defend, however predictive it is. The second is documented training data provenance. You must be able to state what the model was trained on, where it came from, and what it represents, because if the training data encodes historical bias, lending patterns that disadvantaged a protected group, the model reproduces that bias at scale under a veneer of objectivity, and without provenance you cannot even investigate whether it is happening. The third is a governance chain connecting each live decision back to governed source data, so that when an applicant is declined you can produce an unbroken trace: this decision, from this model version, using these features, computed from these records. That chain is what turns an opaque output into an actual explanation, and regulators do not accept opacity as one.
There is a fourth requirement that lives after deployment rather than before it. A credit model does not stay correct on its own, because the population it scores drifts: economic conditions change, applicant behavior shifts, and the relationships the model learned weaken over time. A score that was well-calibrated at launch can quietly degrade until it is approving risk it should decline, and in a regulated setting that drift is not just a performance problem but an examination exposure. So the use case includes ongoing monitoring of model performance and stability, periodic revalidation, and a documented process for retraining or retiring a model when it drifts, with the same lineage discipline applied to each new version so the audit trail never breaks. A model nobody is watching is a model nobody can defend.
This is why the data work here is the use case rather than a supporting task. Without lineage, provenance, and an explainability chain, the model cannot lawfully or safely operate in production, no matter how well it backtests.
What to ask, prepare, and implement
Ask whether you can reconstruct every feature the model uses from source through transformation, document what it was trained on, and trace any single decision back to governed source data without hesitation. Prepare by building governed data pipelines and feature lineage before deployment, and by testing the model for disparate impact as a standard step, not a special investigation. Implement with explainability and documentation as first-class deliverables: an audit-ready record for every decision, model documentation a regulator can review, and a defined process for handling and explaining adverse decisions to applicants.
Resources to make it land
On people and roles, this use case is people-heavy on governance: a business owner in risk, a model risk management or model governance function, compliance and legal involvement, data engineering to build traceable pipelines, and data science for the model itself. On skills and external help, the differentiating skills are model risk governance, regulatory compliance, and feature lineage engineering rather than modeling alone; many institutions bring in outside model validation and regulatory expertise precisely because defensibility is where examinations focus. On data work and tooling, expect to invest in governed data pipelines with full lineage, a documented and version-controlled feature store, training-data provenance records, bias and disparate-impact testing, and tooling that produces an audit trail for every decision.
The readiness questions are these. Can you reconstruct every model feature from its source data? Can you document the training data and demonstrate the model was tested for disparate impact? Can you trace any individual live decision back to governed source data and explain it to an examiner? If the answer to any is no, the model is not ready for a regulated production environment regardless of its accuracy, and the real question is whether you are prepared to build the lineage, provenance, and explainability foundation before deployment rather than after an examination forces it.