The business value belongs to HR, and it should be defined by HR before any prediction starts shaping a decision about a person's career. The outcome is better retention, more grounded workforce planning, and faster internal mobility, achieved by predicting attrition risk early enough to act and matching employees to open roles instead of running a long external search. The owner is the CHRO, with HR business partners and the talent team holding the operational results; the metrics are regretted attrition, internal fill rate, and time-to-fill. If those are not named and a baseline is not captured, the model becomes a dashboard people glance at rather than a capability that changed who stayed and who advanced.
Most HR platforms embed these models, trained on exactly the shape of data the people system already holds: tenure, role history, compensation, performance ratings, engagement results, promotion timing. You enable it and get useful signal quickly, which places it toward the easier end of the delivery range, on data the vendor already governs. That is a genuine advantage. It is also where the honest part begins, because this use case carries a risk most easy wins do not, and HR data is deceptively dirty in ways that bear directly on these specific predictions.
What it actually takes to deliver
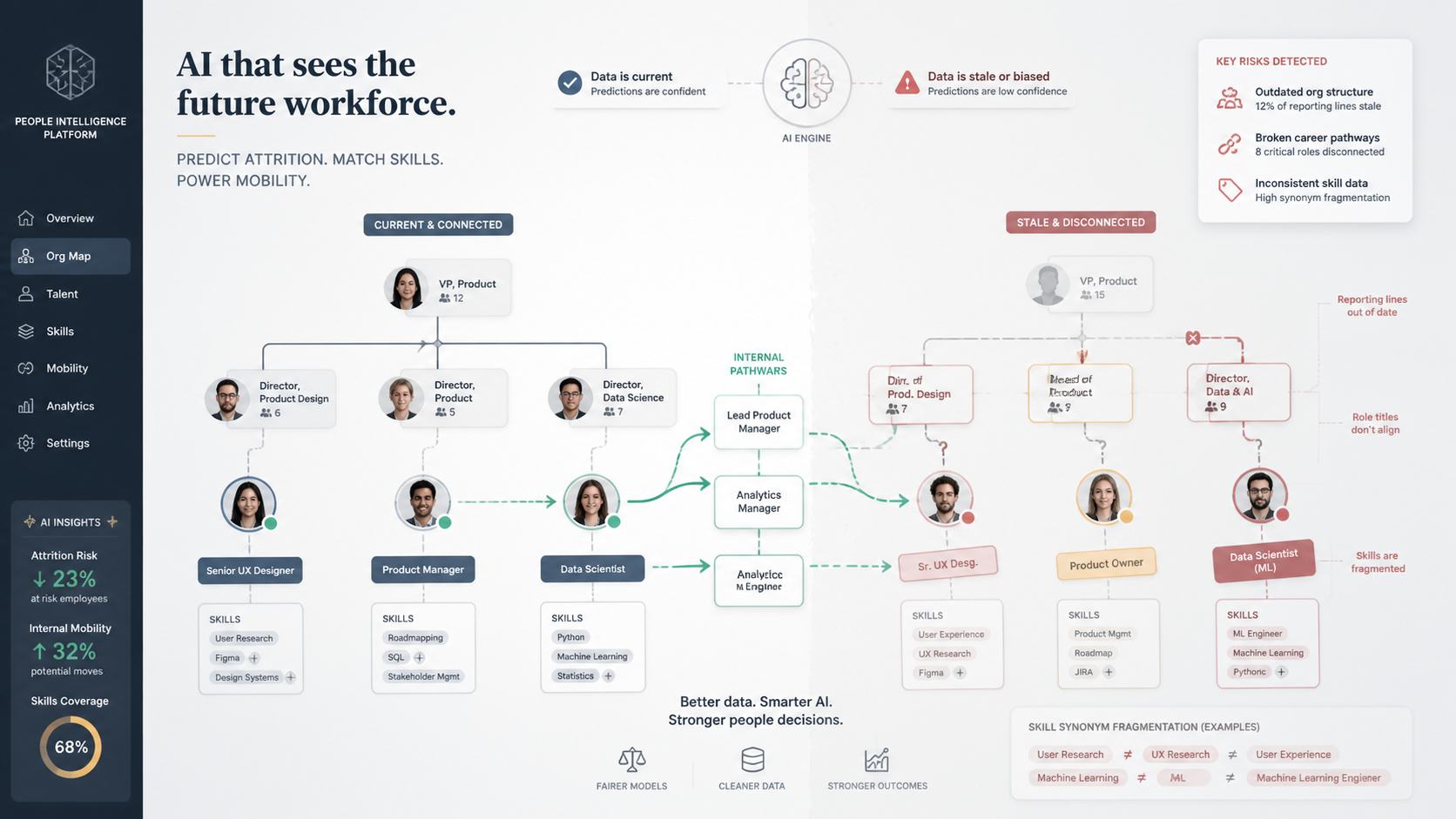
Start with organizational structure. Both attrition modeling and skills matching depend on knowing who reports to whom, which team a person sits on, what their role actually is, and how roles relate. In many organizations this data lags reality. Reorganizations happen faster than the system is updated, titles no longer describe actual work, and reporting lines in the system disagree with how work flows. The model treats that structure as ground truth and builds predictions on a map of the organization months out of date. A flight-risk score that assumes someone reports to a manager they left a year ago is reasoning from stale structure, and embedded does not fix it, because the vendor governs the model, not your org data.
Then there is the skills taxonomy. Matching works only if skills are described consistently. If one part of the company labels a capability data analysis, another calls the same thing analytics, and a third splits it into three sub-skills, the engine cannot recognize them as the same competency. The taxonomy has to be maintained, governed, and applied consistently, and in most organizations it is an afterthought that decays soon after it is created. An ungoverned taxonomy surfaces irrelevant matches and misses obvious internal candidates, and the talent team quietly stops trusting it.
The deepest issue is that the model learns from history, and organizational history encodes the organization's past biases. An attrition or promotion-readiness model trained on past patterns learns who advanced, who stayed, and who was promoted under the conditions that actually prevailed, including whatever bias was present in them. If certain groups were historically overlooked, the model learns to overlook them and does so at scale with the appearance of objectivity. It is not predicting the organization's future needs. It is reproducing the organization's past and presenting that reproduction as insight.
What makes this consequential is not only inaccuracy. It is that ungoverned data produces predictions that are difficult to defend to the employees they concern and to the regulators who protect them. When an attrition model flags an employee, a manager acts on the flag, and the employee later asks why they were treated a certain way, the organization has to explain the basis. When a skills-matching engine consistently fails to surface candidates from a particular group for advancement, that pattern is not just a quality issue; it is potential evidence of disparate impact, the kind of thing that surfaces in a discrimination claim. HR decisions are among the most scrutinized an organization makes, and a model that influences them inherits that scrutiny in full. A prediction built on ungoverned org data and an unmaintained taxonomy, learned from a biased history, cannot be defended when challenged, because the organization cannot show it reflects legitimate, current, fairly derived factors rather than stale structure and encoded bias.
What to ask, prepare, and implement
Ask whether your organizational structure data is current and governed or lags actual reporting reality, whether your skills taxonomy is maintained and applied consistently, and whether you have tested the model's outputs for bias against the workforce you want rather than the one you used to have. Prepare by getting org data current and owned, governing the taxonomy, and making disparate-impact testing a standard step rather than a special investigation. Implement with the predictions positioned as input to a human decision, not an automated verdict, and with a defined way to explain any individual prediction to the employee it concerns. Treat the embedded feature as the prompt to do this governance, because a polished output can otherwise convince leadership the people-data problem is solved when it has merely been automated and accelerated.
Resources to make it land
On people and roles, you need a business owner in HR who holds the outcome, an owner for organizational and role data who keeps it current, and a steward for the skills taxonomy. Legal and compliance belong in the room early, because defensibility is part of the deliverable here, not a downstream check. You do not need to build the models; you need to govern what feeds them.
On skills and external help, the differentiating capability is people-data governance and bias testing rather than modeling, and many organizations bring in outside expertise on disparate-impact analysis and HR-AI compliance precisely because that is where scrutiny concentrates and internal experience is thin. On data work and tooling, expect to invest in governed organizational and role data kept current, a maintained and consistently applied skills taxonomy, and a testing process that checks model outputs for bias against the organization's stated goals. That governed org data and maintained taxonomy pay beyond these two predictions; they are foundational to workforce planning and any internal talent marketplace you build later.
The readiness questions are these. Is your organizational structure data current and governed, or does it lag actual reporting and role reality? Is your skills taxonomy maintained and applied consistently across the company? Have you tested the model's outputs for bias against the workforce you are trying to build rather than the one you used to have? If the answers are no, the question is not whether the model produces credible-looking scores, because it will, but whether you are prepared to govern the underlying data before those scores start shaping decisions you will later have to defend to employees and regulators.