The business value belongs to the operating functions that field repetitive questions, HR, IT, and operations, and it should be named by them before the tool is turned on. The outcome is higher employee productivity, faster access to institutional knowledge, and fewer tier-one tickets, achieved by letting employees ask a question in plain language and get a direct answer instead of searching a wiki or filing a request. The owner is the leader whose team absorbs those questions today; the metrics are ticket deflection, time-to-answer, and adoption. If those are not named and a baseline is not captured, the chatbot becomes something you launched rather than a result you can point to, and the conversation drifts to how clever the demo was instead of whether anyone is actually faster.
Vendor platforms make the start look trivial. Point the tool at a document repository and it begins answering within days, which is why so many organizations deploy before understanding what trustworthy operation requires. It tends to sit at the easy end of the delivery range, on content the vendor's retrieval layer can index immediately. That speed is real. It is also the source of the trouble, because fast and trustworthy are not the same thing, and the gap between them is exactly where the risk lives.
What it actually takes to deliver
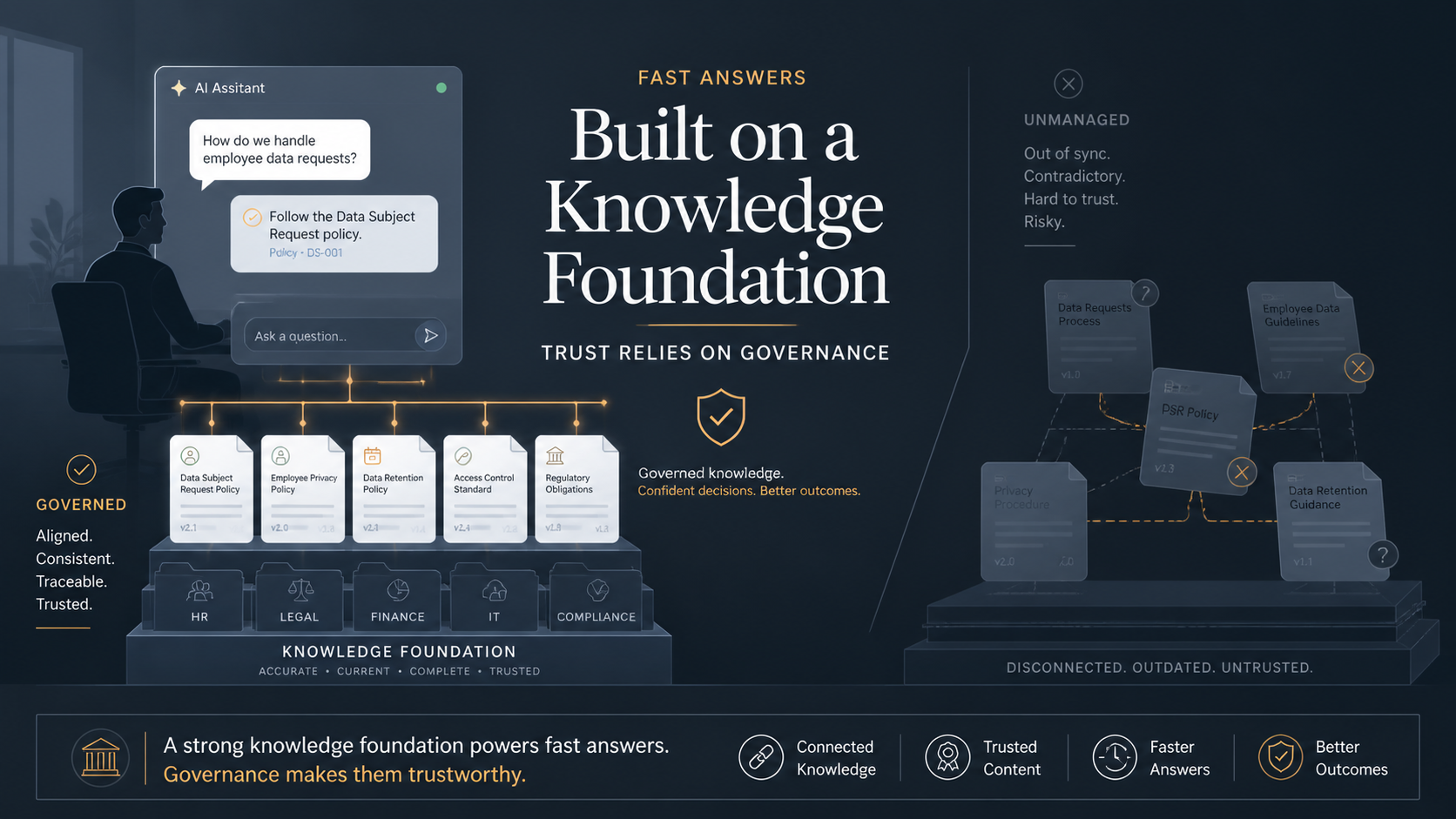
The honest requirement is that the answer is only as good as the knowledge underneath it, and for most organizations that knowledge is stale, inconsistent, or never governed. The chatbot does not correct that. It amplifies it, because it strips away the cues a human would have used to be skeptical.
Consider what a typical enterprise repository holds. Current policies sit beside superseded ones, often in the same folder, with no machine-readable signal indicating which is authoritative. Several documents describe the same process, written by different teams at different times, contradicting each other in details no one reconciled. Runbooks accurate when written have drifted from current practice. A person navigating this checks the date, knows which team's version to trust, and asks a colleague when something looks off. The chatbot applies none of that judgment. It retrieves what matches the query and renders it in fluent, confident prose, and the fluency is the problem, because it removes every signal that would prompt doubt. An employee who asks about parental leave and gets a confident answer drawn from a policy superseded months ago has no way to know the answer is wrong.
This is the part the vendor tool does not supply. Trustworthy operation needs governed knowledge sources, with a maintained answer to which document is authoritative for each topic and a way to mark superseded content so the retrieval layer never serves it as current. It needs defined refresh cycles, so when a policy changes the source the bot draws on is updated on a known schedule rather than whenever someone remembers, with a named owner for each knowledge domain. And it needs lineage, so every answer can be traced to the specific source it came from and the date that source was last validated. That traceability is what makes an answer verifiable rather than oracular. Pointed at an unmanaged document store, the tool is right often enough to be trusted and wrong often enough to be dangerous, with the errors concentrated precisely in the stale and contradictory areas where employees most need reliable help.
There is a second cost that does not show up in a ticket-deflection metric. An internal chatbot built on ungoverned content does not merely underperform; it erodes trust in AI across the organization at the moment that trust is being formed. Early in adoption, a broad population of employees develops a general impression of whether these tools can be relied on, and that impression generalizes. If the first AI tool many of them use confidently tells them wrong things about their own benefits and processes, they do not conclude that one chatbot has a stale knowledge base. They conclude the organization's AI is unreliable, and they carry that into every later initiative, including ones that would have worked.
What to ask, prepare, and implement
Ask, for the topics the chatbot will cover, whether there is a clear and maintained source of truth and a defined refresh cycle, and whether every answer can be traced to an authoritative source. Prepare by governing a bounded set of high-value, high-confidence knowledge before deployment rather than after, designating an owner for each domain, and marking superseded content so it is never served as current. Implement on that governed set first and expand scope only as fast as the governance can extend, because a bot that answers a narrow set of questions correctly builds trust while one that answers everything, including what it gets wrong, spends it. Resist the pressure for broad coverage on day one. The easiest way to deliver breadth is to point the tool at everything, and that is precisely the move that turns a trust-building tool into a trust-eroding one.
Resources to make it land
On people and roles, the essential one is a knowledge owner, or a small set of domain owners, accountable for what is true in each area the bot covers, plus a business sponsor in the function absorbing the questions today. You do not need a data science team. You need someone whose job includes keeping the authoritative sources current.
On skills and external help, the deployment itself is largely configuration and content curation, well within reach of an internal team that understands the platform. Where outside help earns its place is the harder, less glamorous work of standing up knowledge governance, defining authority and refresh discipline for a content estate that has never had it, which is more an information-management capability than a modeling one. On data work and tooling, the requirement is a governed knowledge source with clear authority per topic, a mechanism to flag superseded content, defined refresh cycles, and a retrieval setup that preserves answer-to-source lineage so currency can be checked.
The readiness questions are these. For the topics the chatbot will cover, is there a clear, maintained source of truth and a defined refresh cycle? Can every answer be traced to an authoritative source? And do you have an owner for each knowledge domain who keeps it current? If those are yes for a bounded set of knowledge, you are ready to deploy on that set and grow from there. If not, the question is not how quickly you can get a chatbot answering questions, but whether you are prepared to govern the knowledge layer first, or willing to let employees' first impression of your AI be that it cannot be trusted.